第五章 Linux文件权限与目录配置
Linux最优秀的地方之一就在于他的多用户多任务环境。而为了让各个使用者具有较保密的文件数据,因此文件的权限管理就变的很重要了。Linux一般将文件可存取的身份分为三个类别,分别是owner\/ group \/ others,且三种身份各有read \/ write \/execute等权限。
使用者与群组
文件拥有者
Linux是个多用户多任务的系统,因此可能常常会有多人同时使用这部主机来进行工作。考虑到每个人的隐私权与喜好的工作环境,文件拥有者就相当重要。可以设置适当的权限,让一些隐私的文件只有自己才能访问。
群组概念
经由简易的文件权限设置,就能限制非自己团队(亦即群组)的其他人不能够阅览内容,也可以让自己团队成员可以修改我所创建的文件。同时自己还有私人隐密文件,仍然可以设置让自己团队成员也看不到自己的文件数据。
其他人的概念
就是不属于群组的其他人喽。
root
想访问谁就访问谁。
Linux使用者身份与群组记录的文件
在我们Linux系统当中,默认的情况下,所有的系统上的帐号与一般身份使用者,还有那个root的相关信息,都是记录在\/ etc\/ passwd这个文件内的。至于个人的密码则是记录在\/ etc \/ shadow这个文件下。此外,Linux所有的群组名称都纪录在\/ etc \/ group内!这三个文件可以说是Linux系统里面帐号、密码、群组信息的集中地。
Linux文件权限概念
Linux文件属性
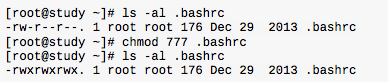
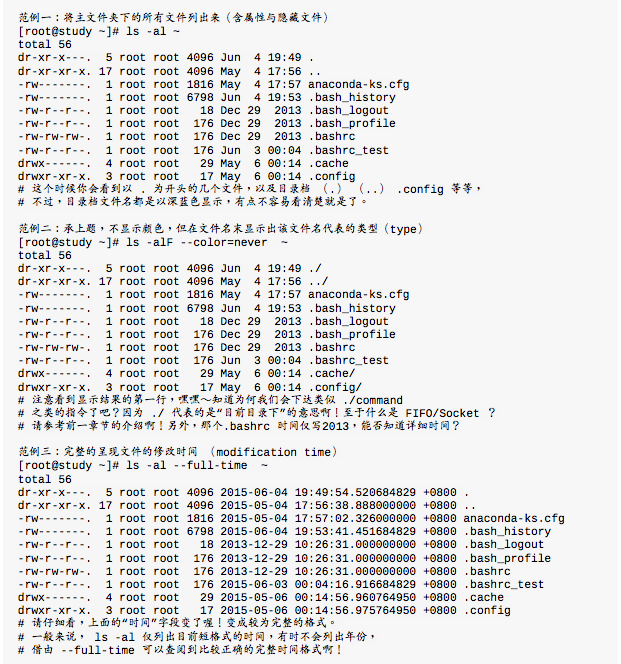
先登录系统,使用su - 切换身份成为root,下达ls -al。 ls是list的意思,重点在显示文件的文件名与相关属性。选项“-al”则表示列出所有的文件详细的权限与属性(包含隐藏文件,就是第一个字符为“.”的文件)。不建议直接使用root登录系统,建议使用su - 来切换身份,离开su - 则使用exit回到登录时的身份即可。运行结果如下: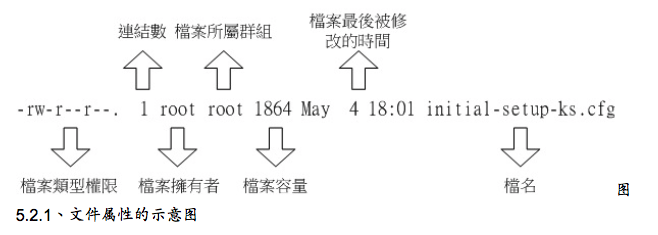
档案类型

i-node
每个文件都会将他的权限与属性记录到文件系统的i-node中,我们使用的目录树是使用文件名来记录,因此每个文件名就会链接到一个i-node,这个属性记录的,就是有多少不同的文件名连接到同一个i-node号码。
容量大小
默认单位为Bytes。
如何改变文件属性与权限
改变所属群组,chgrp
要被改变的群组名称必须要在\/ etc \/group文件中存在才行,否则就会显示错误。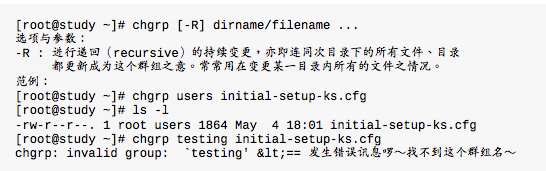
改变文件拥有者,chown
使用者必须是已经存在系统中的账号,也就是在\/ etc \/ passwd这个文件中有记录的使用者名称才能改变。chown还可以顺便直接修改群组的名称,如果要连目录下的所有次目录或文件同时更改文件拥有者的话,直接加上-R选项即可。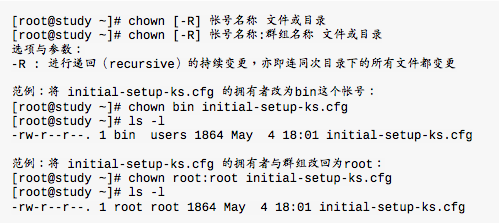
由于复制行为(cp)会复制执行者的属性和权限,把自己的文件复制给使用者,那他仍然无法修改。所以就有必要将这个文件的拥有者与群组修改一下。
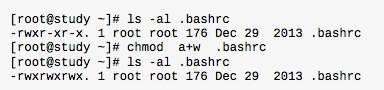
改变权限,chmod

等我们设置权限变更时,该文件的权限数字就是770啦,变更权限的指令chmod的语法:
也可以使用符号类型改变文件权限。
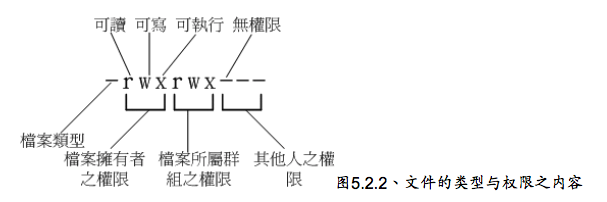
user(u)具有可读、可写、可执行的权限。
group与others(g/o)具有可读与执行的权限。
a代表上面三个身份


目录与文件之权限意义
文件是实际含有数据的地方,包括一般文本文件、数据库内容档、二进制可执行文件(binary program)等等。因此,权限对于文件来说,他的意义是这样的:
- r(read):可读取此一文件的实际内容,如读取文本文件的文字内容。
- w(write):可以编辑、新增或者是修改该文件的内容(但不含删除该文件);
- x(eXecute):该文件具有可以被系统执行的权限。
可执行x,在Windows下是借由扩展名来判断的,例如.exe,.bat,.com等等,但是在Linux下,我们的文件是否能被执行,则是由是否具有x这个权限来决定的,跟文件名没有绝对的关系。对一个文件具有w权限时,可以具有写入、编辑、新增、修改文件的内容的权限,但并不具备删除该文件本身的权限。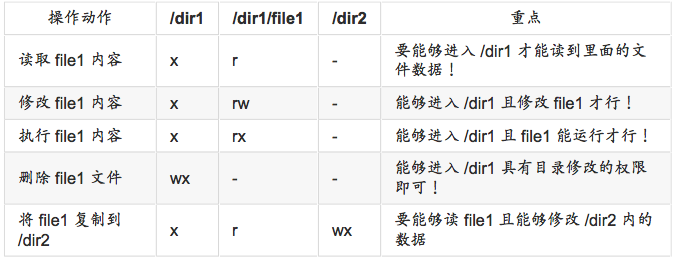
Linux文件种类与扩展名
正规文件(regular file)
第一个字符为【-】。又大略分为:
- 纯文本文件(ASCII)
- 二进制档(binary)
- 数据格式文件(data)
目录(directory)
第一个属性为[d]。链接文件(link)
就是类似Windows系统下的捷径,第一个属性为[l]。设备与设备文件
与系统周边及存储相关的一些文件,通常都集中在/dev这个目录下。 - 区块(block)设备文件:就是一些储存数据,以提供系统随机存取的周边设备,比如硬盘,可查看/ dev / sda,会发现第一个属性为[b]。
- 字符(character)设备文件:即一些序列的周边设备,如键盘鼠标,特点是一次性读取不能够截断输出。如不可能让鼠标调到另一个画面,而是连续滑到另一个地方,第一个属性为[c]。
- 数据接口文件(sockets):这类文件通常被用在网络上的数据承接,我们可以启动一个程序来监听用户端的要求,而用户端就可以通过这个socket来进行数据的沟通了。第一个属性为【s】,最常在\/ run或\/ tmp这些目录中看到这种文件类型。
- 数据输送档(FIFO,pipe):FIFO也是一种特殊的文件类型,主要目的在解决多个程序同时存取一个文件所造成的错误问题。FIFO是first-in-first-out的缩写。第一个属性为[p]。
Linux链接文件就可以简单的视为文件或目录的快捷方式。x只是代表这个文件具有可以执行的权限,并不一定能执行成功,还得看文件的内容。Linux系统的文件名只是了解该文件可能的用途而已,真正的执行与否仍需权限的规范才行。
Linux文件长度的限制。单一文件或目录最大容许文件名为255Bytes,以一个ASCII英文占用一个Bytes来说,则可达255个字符长度,若是以每个中文字2Bytes来说,最大文件名就是在128个中文字符。Linux文件是相当长的文件名,我们希望Linux文件名称可以一看就知道该文件在干嘛,所以文件名通常是很长很长。文件名最好可以避免一些特殊字符。
Linux目录配置
Linux目录配置的依据—FHS
Linux目录配置的标准Filesystem Hierachy Standard(FHS)。
根据FHS[2]的标准文件指出,他们的主要目的是希望让使用者可以了解到已安装软件通常放置于那个目录下,所以他们希望独立的软件开发商、操作系统制作者 、以及想要维护 系统的使用者,都能够遵循FHS的标准。也就是说,FHS的重点在于规范每个特定的目录下应该要放置什么样子的数据而已。这样做好处非常多,因为Linux操作系统就能够在既有的面貌下(目录架构不变)发展出开发者想要的独特风格。
上表右移。
FHS针对目录树架构仅定义了三层目录。
- \/ (root,根目录):与开机系统有关。
- \/ usr (unix software resource):与软件安装/ 执行有关。
- /var(variable):与系统运行过程有关。
根目录(/)的意义与内容
根目录是整个系统最重要的一个目录,因为不但所有的目录都是由根目录衍生出来的,同时根目录也与开机/ 还原 / 系统修复等动作有关。由于系统开机时需要特定的开机软件、核心文件、开机所需程序、函数库等等文件数据,若系统出现错误时,根目录也必须要包含有能够修复文件系统的程序才行。因为根目录是这么的重要,所以在FHS的要求方面,他希望根目录不要放在非常大的分区内,因为越大的分区你会放入越多的数据,如此一来根目录所在分区就可能会有较多发生错误的机会。因此FHS标准建议:根目录所在分区应该越小越好,且应用程序所安装的软件最好不要与根目录放在同一个分区内,保持根目录越小越好。如此不但性能较佳,根目录所在的文件系统也较不容易发生问题。
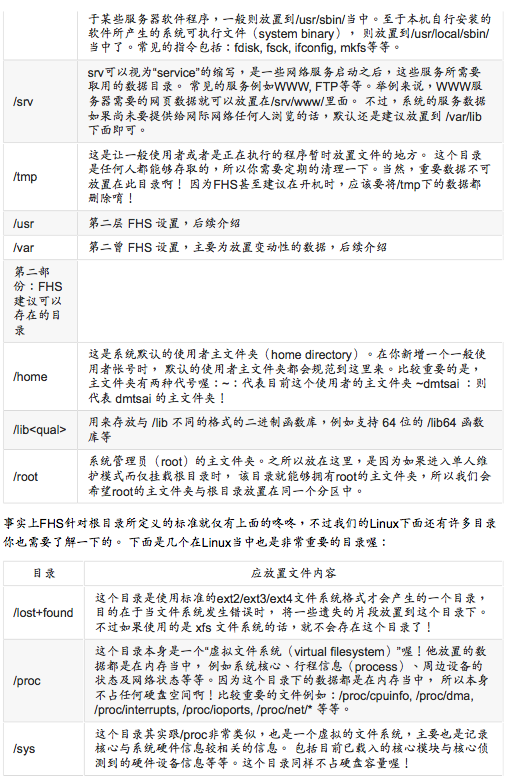
usr的意义与内容
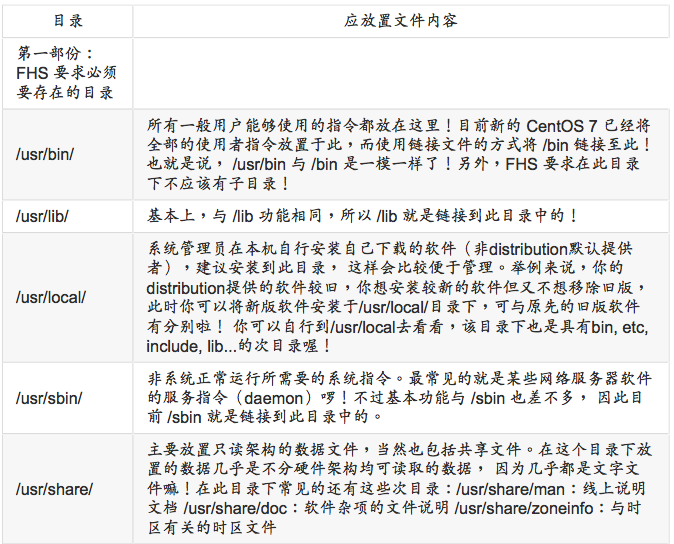

var的意义与内容
如果_usr是安装时会占用较大硬盘容量的目录,那么_var就是在系统运行后才会渐渐占用硬盘容量的目录。因为Ivar目录主要针对常态性变动的文件,包括高速缓存 (cache)、登录文件(log file)以及某些软件运行所产生的文件,包括程序文件(lock file, run file),或者例如MySQL数据库的文件等等。常见的次目录有:
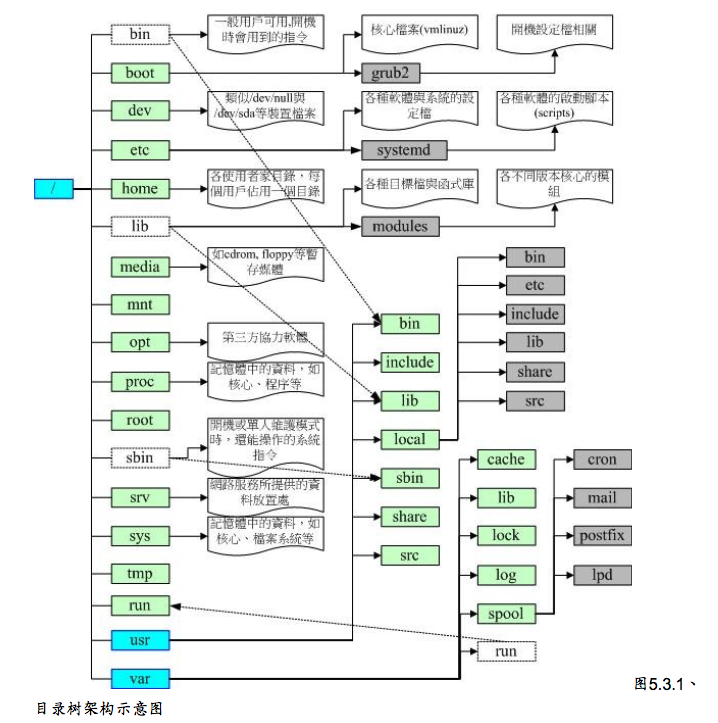
目录树
绝对路径与相对路径


Linux文件与目录管理
目录与路径
目录的相关操作

cd(change directory,变换目录)

pwd(显示目前所在的目录)

mkdir(创建新目录)

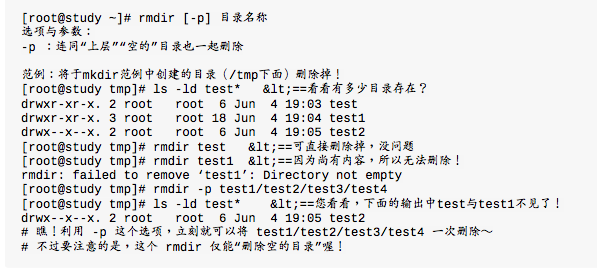
rmdir(删除“空”的目录)
关于可执行文件路径的变量:$PATH
当我们在执行一个指令的时候,如”Is”,系统会依照PATH的设置去每个PATH定义的目录下搜寻文件名为Is的可可执行文件,如果在PATH定义的目 录中含有多个文件名为ls的可可执行文件,那么先搜寻到的同名指令先被执行。
echo有显示、印出的意思,而PATH前面的$表示后面接的是变量。
PATH(一定是大写)这个变量的内容是由一堆目录所组成的,每个目录中由冒号来隔开,每个目录是有顺序之分的。
- 不同身份使用者默认的PATH不同,默认能够随意执行的指令也不同(如root与dmtsai);
- PATH是可以修改的;
- 使用绝对路径或是相对路径直接指定某个指令的文件名来执行会比搜寻PATH来的正确;
- 指令应该放置到正确的目录下执行才会比较方便;
- 本目录(.)最好不要放到PATH中。
文件与目录管理
文件与目录的检视 ls

复制,删除与移动:cp,rm,mv
cp(复制文件或目录)

复制(cp)这个指令是非常重要的,不同身份者执行这个指令会有不同的结果产生,尤其是-a-p选项对于不同身份差别非常大。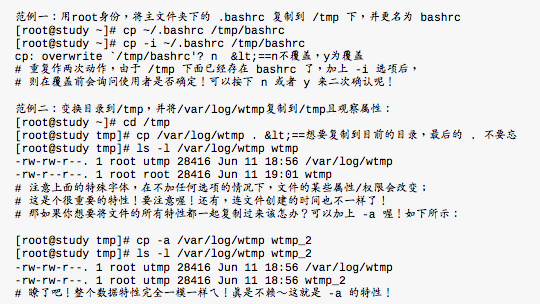
在默认中,cp的来源文件与目的文件的权限是不同的,目的文件的拥有者通常会是指令操作者本身。由于这个特性,我们在进行备份时,某些需要特别注意的特殊权限文件,例如密码档以及配置文件就不能直接以cp复制,而必须加-a
或者是-p等等可以完整复制文件权限的选项才行。如果想要复制文件给其他的使用者,也必须要注意到文件的权限(包含读写执行以及文件拥有者等等)否则其他人还是无法针对你给予的文件进行修订动作。
-l -s都会创建所谓的链接文件(link file),但是这两种链接文件却有不一样的情况, -s是符号链接, -l是实体链接。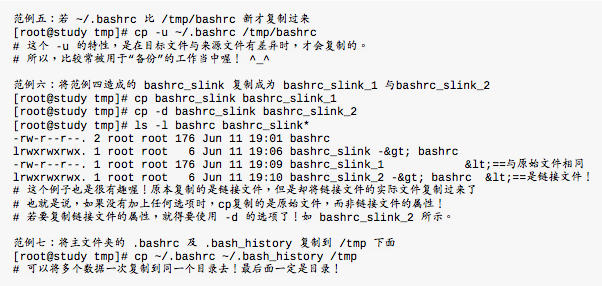
在复制时,需要清楚的了解到
- 是否完整的保留来源文件信息
- 来源文件是否为链接文件
- 来源文件是否为特殊文件,例如FIFO,socket
- 来源文件是否为目录
rm(移除文件或目录)

这是移除的指令(remove) , 要注意的是,通常在Linux系统下,为了怕文件被root误杀,所以很多distributions都已经默认加入i这个选项了!而如果要连目录下的东西都一起杀掉的话,例如子目录里面还有子目录时,那就要使用一这个选项了!不过,使用”rm-r”这个指令之前,请千万注意了,因为该目录或文件“肯定”会被root杀掉!因为系统不会再次询问你是否要砍掉呦!所以那是个超级严重的指令下达呦!得特别注意!不过,如果你确定该目录不要了,那么使用rm-r来循环杀掉是不错的方式!
mv(移动文件与目录,或更名)

这是搬运(move)的意思,当要移动文件或目录时这个指令就很重要了,还有一个用途就是更改文件名,这是Linux才有的指令,还有个rename指令可以用来更改大量文件的文件名。
取得路径的文件名称与目录名称

basename与dirname的用途。
文件内容查阅
- cat由第一行开始显示文件内容
- tac从最后一行开始显示,可以看出tac是cat的倒着写
- nl显示的时候,顺便输出行号
- more一页一页的显示文件内容
- less与more类似,但是比more更好的是可以往前翻页
- head只看头几行
- tail只看尾巴几行
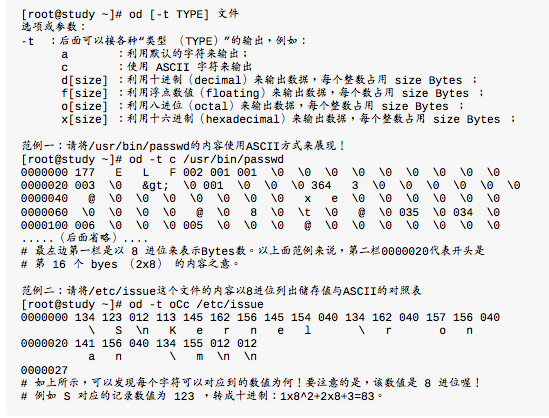
- od以二进制的方式读取文件内容
直接检视文件内容
cat(concatenate)

数据选择
head(取出前面几行)

tail(取出后面几行)

非纯文本文件od
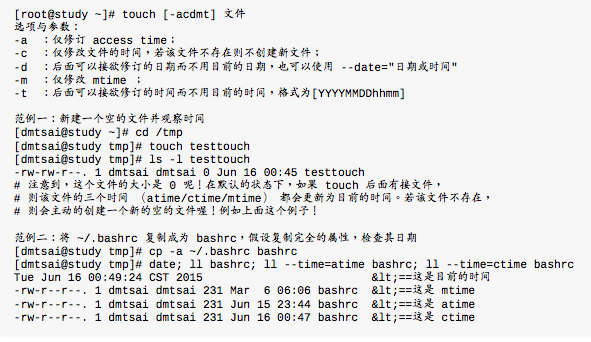
修改文件时间或创建新文件:touch
- modification time(mtime):当该文件的内容数据变更时,就会更新这个时间,内容数据指的是文件的内容,而不是文件的属性或权限。
- status time(ctime):当该文件的状态改变时就会更新这个时间,比如权限与属性被改变了,就会更新这个时间。
- access time(atime):当该文件的内容被取用时就会更新这个读取时间。如使用cat去读取,就会更新该文件的atime。
文件与目录的默认权限与隐藏权限
文件默认权限:umask
umask就是指定目前使用者在创建文件或目录时候的权限默认值。
文件隐藏属性
chattr(设置文件隐藏属性)

这些指令是很重要的,尤其是在系统数据安全上面。
lsattr(显示文件隐藏属性)

使用chattr设置后,可以使用lsattr来查阅隐藏的属性。
文件特殊权限:SUID,SGID,SBIT
Set UID
当s这个标志出现在文件拥有者的x权限上时,如- rwsr - xr - x就称为Set UID,简称为SUID。SUID的限制与功能:
- SUID权限仅对二进制程序有效
- 执行者对于该程序需要有x的可执行权限
- 本权限仅在执行该程序的过程中有效
- 执行者将具有该程序拥有者的权限。
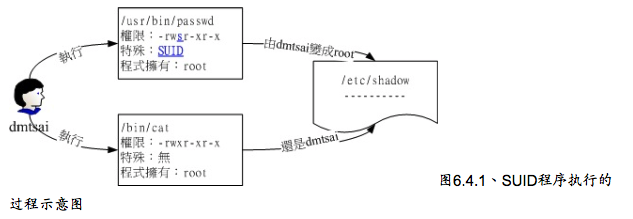
SUID仅可以用在binary program上,不能用在shell script上,这是因为shell script知识将很多binary可执行文件加进来执行而已。所以SUID的权限部分,还是得看shell script调用进来的程序设置,SUID对于目录也是无效的。
Set GID
与SUID不同的是,SGID可以针对文件或目录来设置。对于文件,SGID有如下的功能:
- SGID对二进制程序有用
- 程序执行着对于该程序来说,需具备x的权限
- 执行者在执行的过程中将会获得该程序群组的支持!
Sticky Bit
SBIT目前只针对目录有效,对于文件已经没有效果了。SBIT对于目录的作用是:
- 当使用者对于此目录具有w,x权限,亦即具有写入的权限时。
- 当使用者在该目录下创建文件或目录时,仅有自己与root才有权力删除该文件。
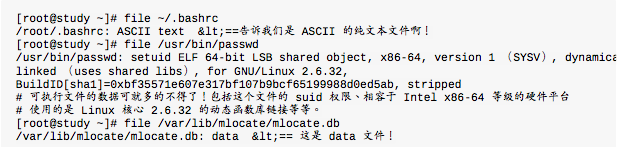
观察文件类型:file
指令与文件的搜寻
指令文件名的搜寻
which(寻找可执行文件)

这个指令是根据”PAT}这个环境变量所规范的路径’去搜寻“可执行文件”的文件名。
文件文件名的搜寻
whereis(由一些特定的目录中寻找文件文件名)
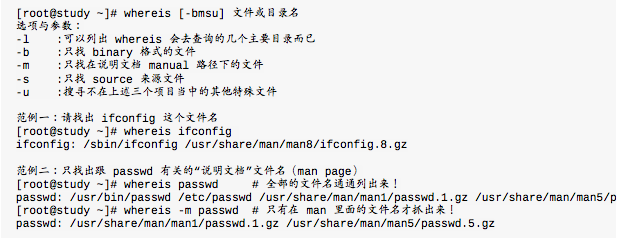
find是很强大的搜寻指令,但时间花费很大,因为find是直接搜寻硬盘。whereis只招几个特定的目录,并没有全系统去查询。whereis主要针对的是/ bin / sbin下面的可执行文件,以及/ usr / share / man下面的man page文件跟几个比较特定的目录来处理。
locate、updatedb

使用locate 来寻找数据的时候特别的快,这是因为locate寻找的数据是由“已创建的数据库/ var / lib / mlocate / “里面的数据所搜寻到的,所以不用直接在去硬盘当中存取数据,当然是很快速的。但是有限制条件,他是由数据库来搜寻的,而数据库每天执行一次,若在数据库更新之前搜寻文件则搜寻不到。
updatedb
根据 / etc / updatedb.conf的设置去搜寻系统硬盘内的文件名,并更新/ rar / lib / mlocate内的数据库文件。
locate
依据 / var / lib / mlocate内的数据库记载,找出使用者输入的关键字文件名。
find



Linux磁盘与文件系统管理
认识Linux文件系统
磁盘组成与分区
文件系统特性
每种操作系统能够使用的文件系统并不相同。举例来说,windows 98以前的微软操作系统主要利用的文件系统是FAT (或FAT16) , windows 2000以后的版本有所谓的NTFS文件系统,至于Linux的正统文件系统则为Ext2 (Linux second extended file system, ext2fs)这一个。此外,在默认的情况下,windows 操作系统是不会认识Linux的Ext2的。
文件系统是如何运行与操作系统的文件数据有关。较新的操作系统的文件数据
除了文件实际内容外,通常含有非常多的属性,例如Linux操作系统的文件权限(rwx)与文件属性(拥有者、群组、时间参数等)。文件系统通常会将这两部份的数据分别存放在不同的区块,权限与属性放置到inode中,至于实际数据则放置到data block区块中。另外,还有一个超级区块 (superblock)会记录整个文件系统的整体信息 ,包括inode与block的总量、使用量、剩余量等。
每个inode与block都有编号,至于这三个数据的意义可以简略说明如下:
- superblock :记录此filesystem的整体信息,包括inode/block的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
- inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的block号码;
- block :实际记录文件的内容,若文件太大时,会占用多个block。
由于每个 inode与 block都有编号而每个文件都会占用一个 inode, inode内有文件数据置的 block号码。因此我们可以知道的是,如果能够找到文件的 inode的话那么自然会知道这个文件所放置数据的 block号码,当然也就能够读出该文件的实际数据了。这是个比较有效率的作法,因此我们的磁盘就能够在短时间内读取出全部的数据,读写的性能比较好。文件系统先格式化出inode与block的区块。inode中记录了4个区块的位置,此乃索引式文件系统。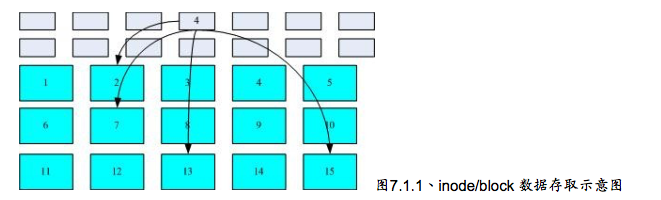
还有一种文件系统比如FAT格式,就是我们惯用的U盘,这种格式是没有inode存在的所以是顺序读取的。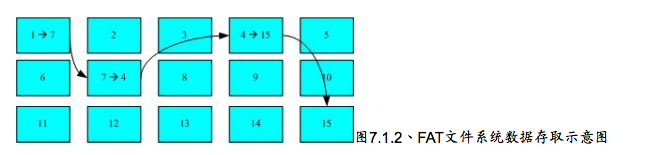
Linux的EXT2文件系统(inode)
inode的内容在记录文件的权展与相关属性,至于bock区块则是在记录文件的实际内容。而且文件系统一开始就将 inode与 block规划好了,除非重新格式化
(或者利用 resize2is等指令变更文件系统大小),否则 inode与 block固定后就不再变动但是如果仔细考虑一下,如果我的文件系统高达数百GB时,那么将所有的 inode与 block通通放置在一起将是很不智的决定,因为 inode与 block的数量太庞大,不容易管理。
为此Ext2文件系统在格式化的时候基本上是区分为多个区块群组,每个区块群组都有独立的inode,block,superblock系统。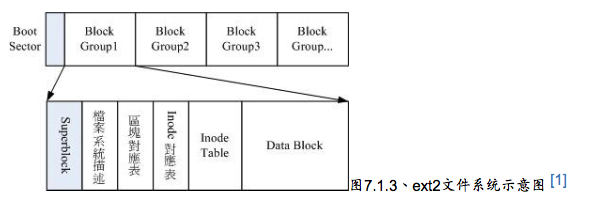
在整体的规划当中,文件系统最前面有一个开机扇区 ( boot sector),这个开机扇区可以安装开机管理程序,这是个非常重要的设计,因为如此一来我们就能够将不同的开机管理程序安装到个别的文件系统最前端,而不用覆盖整颗磁盘唯一的MBR,这样也才能够制作出多重开机的环境啊。
data block(数据区块)
由于block大小的差异,会导致该文件系统能够支持的最大磁盘容量与最大但以文件大小并不相同。
block基本限制如下:
- 原则上,block的大小与数量在格式化完就不能再改变了(除非重新格式化)
- 每个block内最多只能够放置一个文件的数据;
- 承上,如果文件大于block的大小,则一个文件会占用多个block数量;
- 承上,若文件小于block ,则该block的剩余容量就不能够再被使用了(磁盘空间会浪费)
block大小选择所造成的不同问题。选在大的block在存取大量小文件时可能造成浪费。选小的block在存取大文件时索引的数量更多,可能导致文件系统不良的读写性能。事实上,现在的磁盘容量都太大了,所以大家都只会选在4K的block大小。
inode table(inode表格)
inode记录的文件数据至少有下面这些:
- 该文件的存取模式(read / write / excute)
- 该文件的拥有者与群组(owner / group)
- 该文件的容量。
- 该文件创建或状态改变的时间( ctime)
- 最近一次的读取时间( atime)
- 最近修改的时间( mtime)
- 定义文件特性的旗标(fag),如 SetUID
- 该文件真正内容的指向(pointer)
inode的数量与大小也是在格式化时就已经固定了。
- 每个 inode大小均固定为128 Bytes(新的ext4与xfs可设置到256 Bytes);
- 每个文件都仅会占用一个 inode而已;
- 承上,因此文件系统能够创建的文件数量与 inode的数量有关;
- 系统读取文件时需要先找到 inode,并分析 inode所记录的权限与使用者是否符合,若符合才能够开始实际读取 block的内容。
inode要记录的数据非常多,偏偏又只有128Bytes,而inode记录一个block要花掉4Byte,所以有一个巧妙的办法。将inode记录block号码的区域定义为12个直接1个间接一个双间接一个三间接记录区。直接就是直接可以通过号码来取得block,间接就是再拿一个block来当作记录block号码的记录区,如果文件太大,就会使用间接的block来记录号码。
superblock(超级区块)
superblock是记录整个filesystem相关信息的地方,没有superblock就没有filesystem了。记录的信息有:
- block与inode的总量
- 未使用与已使用的inode,block数量
- block与inode的大小
- filesystem的挂载时间,最近一次写入数据的时间,最近一次检验磁盘的时间等文件系统的相关信息。
- 一个valid bit数值,若此文件系统已被挂载,则valid bit为0,若未被挂载,则valid bit为1。
superblock是非常重要的,因为文件系统的基本信息都在,如果superblock死掉了,文件系统要花费很多时间去挽救。一般来说,superblock的大小为1024Bytes,一个文件系统应该仅有一个superblock,除了第一个block group内会含有superblock后续的block group不一定含有superblock。若含有superblock也是为第一个block group内的superblock做备份。
Filesystem Description(文件系统描述说明)
这个区段可以描述每个block group的开始与结束的block号码,以及说明每个区段(superblock, bitmap, inodemap, data block) 分别介于哪一个block号码之间。
block bitmap(区块对照表)
记录使用与未使用block的号码。
inode bitmap(inode对照表)
inode bitmap则是记录使用与未使用的inode号码。
dumpe2fs
与目录树的关系
目录
在Linux下的文件系统创建一个目录,文件系统会分配一个inode与至少一块block给该目录。其中inode与至少一块block给该目录。其中inode记录该目录的相关权限与属性,并可记录分配到的那块block号码。而block则是记录在这个目录下的文件名与该文件名占用的inode号码数据。也就是说目录所占用的block内容在记录如下的信息。
在目录下面的文件数如果太多而导致一个block无法容纳的下所有的文件名与inode对照表,Linux会给予该目录多一个block来继续记录相关的数据。
文件
目录树读取
inode本身并不记录文件名,文件名的记录是在目录的block当中。当我们要读取某个文件时,就务必会经过目录的inode与block然后才能找到那个待读取文件的inode号码,最终才会督导正确的文件的block内的数据。
由于目录树是由根目录开始读起,因此系统通过挂载的信息可以找到挂载点的inode号码,挂载点实际上就是linux中的磁盘文件系统的入口目录。此时就能够得到根目录的inode内容,并依据该inode读取根目录的block内的文件名数据,再一层一层的往下读到正确的文件名。比如读取/ etc / passwd这个文件时的过程。
- / 的inode :通过挂载点的信息找到inode号码为128的根目录inode,且inode规范的权限让我们可以读取该block的内容(有r与x)。
- / 的block: 经过上个步骤取得block的号码,并找到该内容有etc/ 目录的inode号码( 33595521)。
- etc/ 的inode :读取33595521号inode得知dmtsai具有r与x的权限,因此可以读取etc/ 的block内容;
- etc/ 的block :经过上个步骤取得block号码,并找到该内容有passwd文件的inode号码 ( 36628004)
- passwd的inode : 读取36628004号inode得知dmtsai具有r的权限,因此可以读取passwd的block内容;
- passwd的block :最后将该block内容的数据读出来。
EXT2/ EXT3/ EXT4文件的存取与日志式文件系统的功能
若是想要新增一个文件,文件系统的行为是。
- 先确定使用者对于欲新增文件的目录是否具有w与x的权限,若有的话才能新增;
- 根据inode bitmap找到没有使用的inode号码,并将新文件的权限/ 属性写入。
- 根据block bitmap找到没有使用中的block号码,并将实际的数据写入block中,且更新inode的block指向数据;
- 将刚刚写入的inode与block数据同步更新inode bitmap与block bitmap,并更新superblock的内容。
一般来说,我们将inode table与data block称为数据存放区域,至于其他例如superblock、block bitmap与inode bitmap等区段就被称为metadata (中介数据),因为superblock,inode bitmap及block bitmap的数据是经常变动的,每次新增、移除、编辑时都可能会影响到这三个部分的数据,因此才被称为中介数据的啦。
数据的不一致(inconsistent)状态
由于不知名的原因可能导致metadata的内容与实际数据存放区产生不一致(inconsistent)的情况。传统的解决方法会在开机时皆有superblock当中记录的valid bit与filesystem state等状态来判断是否强制进行数据一致性的检查。这样的检查是很费时的。非常麻烦,造成了后来日志式文件系统的兴起。
日志式文件系统(Journaling filesystem)
为了避免文件系统不一致的发生,在filesystem中规划一个区块,该区块专门记录写入或修订文件的步骤,就可以简化一致性检查的步骤。
- 预备:当系统要写入一个文件时,会先在日志记录区块中纪录某个文件准备要写入的信息;
- 实际写入:开始写入文件的权限与数据,开始更新metadata的数据。
- 结束:完成数据与metadata的更新后,在日志记录块当中完成该文件的记录。
万一数据的纪录过程当中发生了问题,那么我们的系统只要去检查日志记录区块,就可以知道哪个文件发生了问题,针对该问题来做一致性的检查即可,而不必针对整块filesystem去检查,这样就可以达到快速修复filesystem的能力。
Linux文件系统的运行
编辑一个好大的文件,在编辑的过程中又频繁的要系统来写入到磁盘中,由于磁盘写入的速度要比内存慢很多, 因此你会常常耗在等待磁盘的写入/读取上,很没效率。为解决效率问题,Linux使用的方式是通过一个非同步处理(asynchronously)的方式。
当系统载入一个文件到内存后,如果该文件没有被更动过,则在内存区段的文件数据会被设置为干净(clean) 的。但如果内存中的文件数据被更改过了(例如你用nano去编辑过这个文件),此时该内存中的数据会被设置为脏的 (Dirty) 。此时所有的动作都还在内存中执行,并没有写入到磁盘中!系统会不定时的将内存中设置为”Dirty”的数据写回磁盘,以保持磁盘与内存数据的一致性。
内存的速度要比磁盘快的多,因此如果能够将常用的文件放置到内存当中,就会增加系统性能。因此我们Linux系统上面文件系统与内存有非常大的关系。
- 系统会将常用的文件数据放置到内存的缓冲区,以加速文件系统的读/ 写;
- 承上,因此Linux的实体内存最后都会被用光!这是正常的情况!可加速系统性能;
- 可以手动使用sync来强迫内存中设置为Dirty的文件回写到磁盘中;
- 若正常关机时,关机指令会主动调用sync来将内存的数据回写入磁盘内;
- 但若不正常关机(如跳电、死机或其他不明原因),由于数据尚未回写到磁盘内, 因此重新开机后可能会花很多时间在进行磁盘检验,甚至可能导致文件系统的损毁(非磁盘损毁)。
挂载点的意义(mount point)
将文件系统与目录树结合的动作我们称为挂载。重点是挂载点一定是目录,该目录为进入该文件系统的入口,因此并不是有任何文件系统都能使用的,必须挂载到目录树的某个目录后,才能够使用该文件系统。
其他Linux支持的文件系统与VFS
Linux的标准文件系统是ext2,且还有增加了日志功能的ext3/ext4,事实上,Linux还有支持很多文件系统格式的,尤其是最近这几年推出了好几种速度很快的日志式文件系统,包括SGI的XFS文件系统, 可以适用更小型文件的Reiserfs 文件系统,以及Windows的FAT文件系统等等,都能够被Linux所支持。
Linux VFS(Virtual Filesystem Switch)
Linux的系统都是通过一个名为Virtual Filesystem Switch 的核心功能去读取filesystem的。也就是说, 整个Linux 认识的filesystem 其实都是VFS在进行
管理,我们使用者并不需要知道每个partition上头的filesystem是什么。VFS会主动的帮我们做好读取的动作。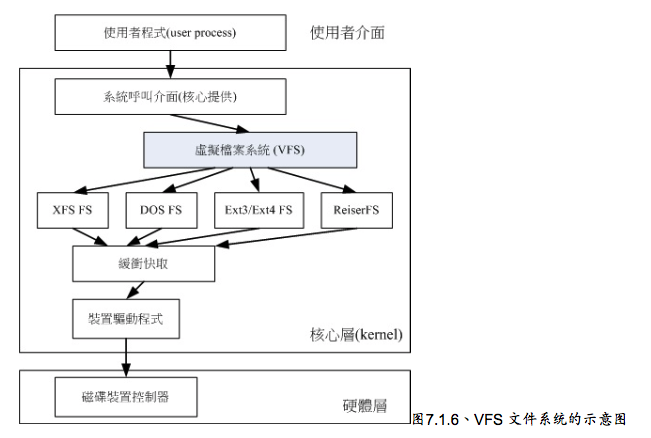
XFS文件系统简介
EXT家族当前较伤脑筋的地方:支持度最广,但格式化超慢。基本上xfs就是一个日志式文件系统。xfs文件系统在数据的分布上主要规划为三个部分,一个是数据区,一个文件系统活动登录区,以及一个实时运行区。
文件系统的简单操作
磁盘与目录的容量
df:列出文件系统的整体磁盘使用量
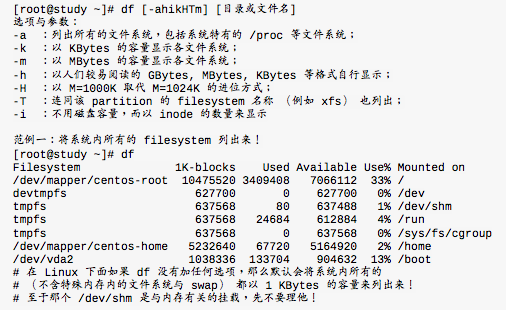
- Filesystem:代表该文件系统是在哪个partition,所以列出设备名称。
- 1k-blocks :说明下面的数字单位是1KB,可利用-h或-m来改变容量。
- Used:顾名思义,就是使用掉的磁盘空间。
- Available :也就是剩下的磁盘空间大小。
- Use% :就是磁盘的使用率。
- Mounted on:就是磁盘挂载的目录所在(挂载点)。
由于df主要读取的数据几乎都是针对一整个文件系统,因此读取的范围主要是在Superblock内的信息,所以这个指令显示结果的速度非常的快速。
du

与df不一样的是,du这个指令其实会到文件系统去搜寻所有的文件数据,所以上述指令运行会执行一小段时间。
实体链接与符号链接:ln
Hard Link(实体链接,硬式链接或实际链接)
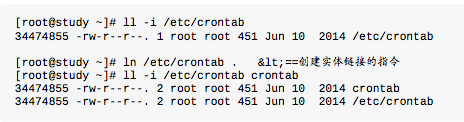
hard link只是在某个目录下新增一笔文件名链接到某inode号码的关联记录而已。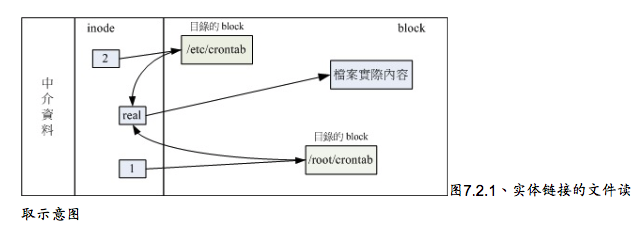
hard link的限制:
- 不能跨Filesystem。
- 不能link目录。链接到目录时,链接的数据需要连同被链接目录下面的所有数据都创建链接。
Sysbolic Link(符号链接,亦是捷径)

Sysbolic link就是在创建一个独立的文件,而这个文件会让数据的读取指向他link的那个文件的文件名。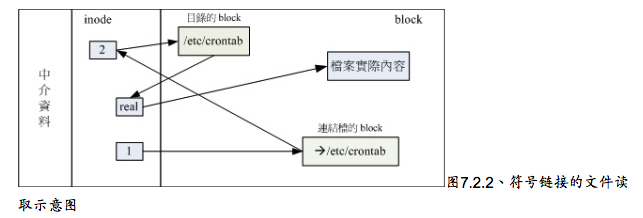
hard link比较安全。但hard link的限制太多了,包括无法做目录的link,用途上还是比较受限的,反而是Symbolic Link的使用较广。
删除动作,如删除/ etc / crontab文件,删除动作只是将 / etc目录下关于crontab的关连数据拿掉而已,crontab所在的inode与block其实都没有被变动。
磁盘的分区,格式化,检验与挂载
若是想在系统中新增一个磁盘,需要:
- 对磁盘进行分区,以创建可用的partition。
- 对该partition进行格式化 (format), 以创建系统可用的filesystem
- 若想要仔细一点,则可对刚刚创建好的filesystem进行检验。
- 在Linux系统上,需要创建挂载点 (亦即是目录) ,并将他挂载上来。
观察磁盘分区状态
lsblk列出系统上所有磁盘列表
Isblk可以看成” list block device”的缩写, 就是列出所有储存设备的意思。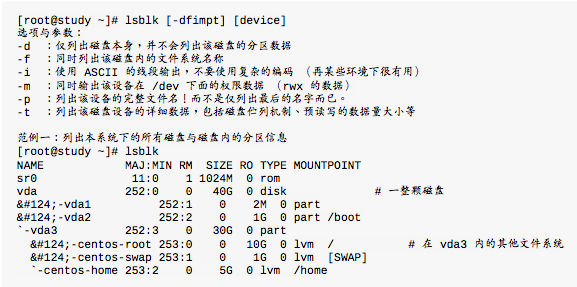
blikid列出设备的UUID等参数
UUID是全域单一识别码(universally unique identifier),Linux会将系统内所有设备都给予一个独一无二的识别码。这个识别码就可以拿来作为挂载或是使用这个设备、文件系统之用了。
parted列出磁盘的分区表类型与分区信息
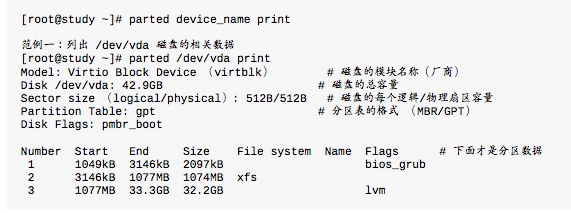
磁盘分区:gdisk/ fdisk
用gdisk新增分区
partprobe更新Linux核心的分区表信息
用gdisk删除一个分区
fdisk
文件系统检验
文件系统挂载与卸载
磁盘、文件系统参数修订
mknod
xfs-admin修改XFS文件系统的UUID与Label name
设置开机挂载
开机挂载/etc/fstab及/etc/mtab
特殊设备loop挂载
内存交换空间(swap)之创建
如果硬件的配备资源足够的话’那么swap应该不会被我们的系统所使用到swaρ会被利用到的时刻通常就是实体内存不足的情况。目前在个人使用上内存已经足够大,不用设置swap也不会有太大的问题,但是服务器就不一定了,由于不知道何时会有大量来自网络的请求,因此最好还是能够预留一些swap来缓冲一下系统的内存用量。有备无患。
使用实体分区创建swap
- 分区:先使用gdik在你的磁盘中分区出一个分区给系统作为swap。由于Linux的gdisk默认会将分区的ID设置为 Linux的文件系统,所以你可能还得要设置一下system ID就是了。
- 格式化∶利用创建swap格式的” mkswap设备文件名”就能够格式化该分区成为swap格式。
- 使用:最后将该swap设备启动,方法为:” swapon设备文件名”。
- 观察:最终通过free与 swapon-s这个指令来观察一下内存的用量。
使用文件创建swap
文件与文件系统的压缩,打包与备份
压缩文件的用途与技术
Linux系统常见的压缩指令
虽然Linux文件的属性基本上是与文件名没有绝对关系的,为了帮助人类,适当的扩展名还是必要的。
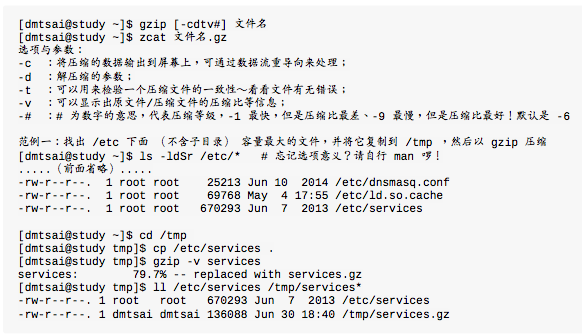
bzip2,bzcat,bzmore,bzless,bzgrep
gzip是为了取代 compress并提供更好的压缩比而成立的,那么bzip2则是为了取代gzip并提供更佳的压缩比而来的。
xz,xzcat,xzmore,xzless,xzgrep
xz的压缩比好很多,但是xz最大的问题就是时间花太久了。运算时间要比gzip久很多。
打包指令:tar
tar
